Optimize GEMM
My gemm optimization on RPi (ARM) achieved a 170x performance boost, showing speeds faster than Eigen and close to OpenBLAS.
GEMM is crucial in AI inference, since it is the core of computations in many layers such as convolution and Transformer. This repo shows how I optimized GEMM by methods like SIMD registers, blocking, tiling, packing, parallel computing to achieve over 170x speed up (0.1747 -> 29.8623 GFLOPS) on Raspberry Pi 4 Model B (4GB RAM) using CPU only, reached the performance level of high-performance linear algebra libraries.
All matrices are row-major and initialized with values from text files, and thus the results should be constant. Once the computation is complete, the sum and elements will print for correctness checks.
Code available here: https://github.com/Avafly/optimize-gemm
Optimization Steps
1. Naive
Basic triple-nested loop to perform gemm. mm_naive.cpp achieved 0.1747 GFLOPS with elapsed time of 27224.92 ms.
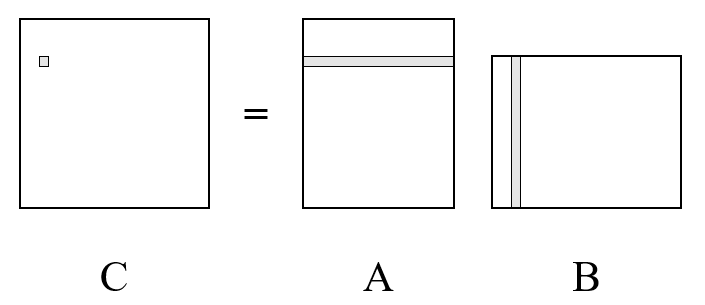
2. 4x4 Kernel
This step used neon registers (SIMD, equivalent to x64's AVX) to process multiple data with single instructions. A 4x4 kernel computes 16 elements of matrix C simultaneously, and elements in A and B only accessed from memory once per k loop instead of four times.
mm_kernel4x4.cpp improved performance to 1.5573 GFLOPS with elapsed time of 3054.31 ms.
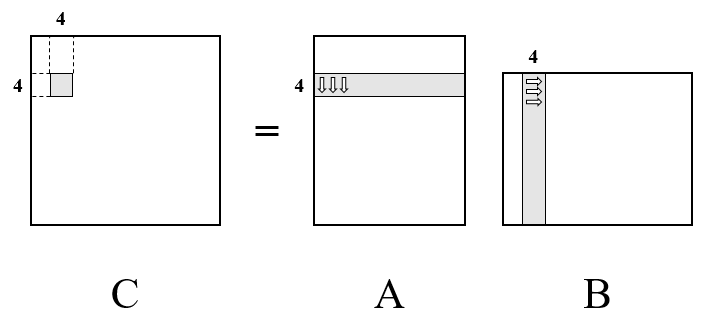
3. 12x8 Kernel
The next step is selecting a suitable kernel size. Cortex-A72 has 32 neon registers, and 20-30 registers is optimal for use. 12x8 was chosen to maximize register utilization, which requires 29 registers total (24 for C, 3 for A, and 2 for B).
mm_kernel12x8.cpp improved performance to 5.5944 GFLOPS with elapsed time of 850.19 ms.
4. Further
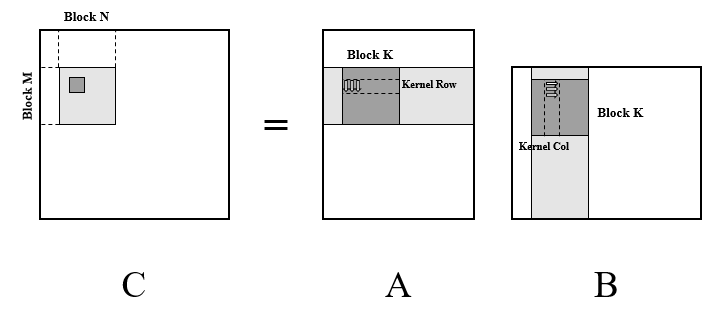
The kernel efficiently utilizes registers, but cache usage remained suboptimal. For large matrices, FLOPS drop significantly due to frequent memory access. This can be addressed with blocking/tiling, which improves cache hit rates by enhancing data locality. Additionally, blocking supports parallel computation very well. Parallelization improves cache and neon register utilization since each core has its own cache and registers. Furthermore, packing the blocks before computation also can enhance data locality.
After completing above optimizations, mm_optimize.cpp improved performance to 29.8623 GFLOPS with elapsed time of 159.28 ms - a 170x speedup compared to the naive implementation! @_@
Some Linear Algebra Libraries
Most linear algebra libraries provide gemm supports, and I tested against some well-known libraries: eigen, openblas, and gsl.
| Elapsed Time (x4) | GFLOPS (x4) | Release Tags | |
|---|---|---|---|
| optimize | 159.28 ms | 29.8623 | - |
| eigen | 242.98 ms | 19.5750 | 3.4.0 |
| openblas | 151.14 ms | 31.4691 | 0.3.28 |
| gsl | 7252.10 ms | 0.6559 | 2.8 |
My gemm outperforms eigen by over 10 GFLOPS and is about 1.6 GFLOPS slower than openblas. Gsl does not provide an efficient implementation by default, resulting in very slow speed (but it can utilize other libs as backends for gemm computation if specified during build).